Data Centered Architecture
Data-centered architecture is an architecture style in which the data is designed first and applications are then designed to create and use it.
The architecture of a system comprises its fundamental concepts or properties embodied in its elements and relationships, and in the principles of its design and evolution. Enterprise architecture is a well-defined practice for developing architectures of enterprises and their component systems, particularly their information technology (IT) systems.
In a data-centered architecture, programs access data at source, rather than exchanging complex information-rich messages. This reduces dependencies between programs and avoids the proliferation of modified versions of the data. The result is systems that are simpler, more robust, and less prone to error. Data-centered architectures are made possible by, and are a natural development of, universal Internet connectivity and the World-Wide Web.
The principles of data-centered architecture can be applied, not just within a single enterprise, but in an ecosystem of enterprises that deal with each other. They support a commercial model in which data providers, as well as application and service providers, can gain rewards for adding value.
The Principles of Data-Centered Architecture
Principles are general rules and guidelines, intended to be enduring and seldom amended, that inform and support the way in which an organization sets about fulfilling its mission. Architecture principles define the underlying general rules and guidelines for the use and deployment of IT resources and assets. They reflect a level of consensus among the various elements of the organization, and form the basis for making future IT decisions. The following principles apply to a data-centered architecture. They are defined in the format of the popular TOGAF® architecture development method, and are freely available for enterprises to amend and use in their architectures.
Interoperation by Data Sharing
The principle of interoperation by data sharing is the fundamemtal principle of data-centered architecture. Applications retrieve the data from its sources, rather than passing copies of it to each other. The design of the applications is determined by the data, not than the other way round.
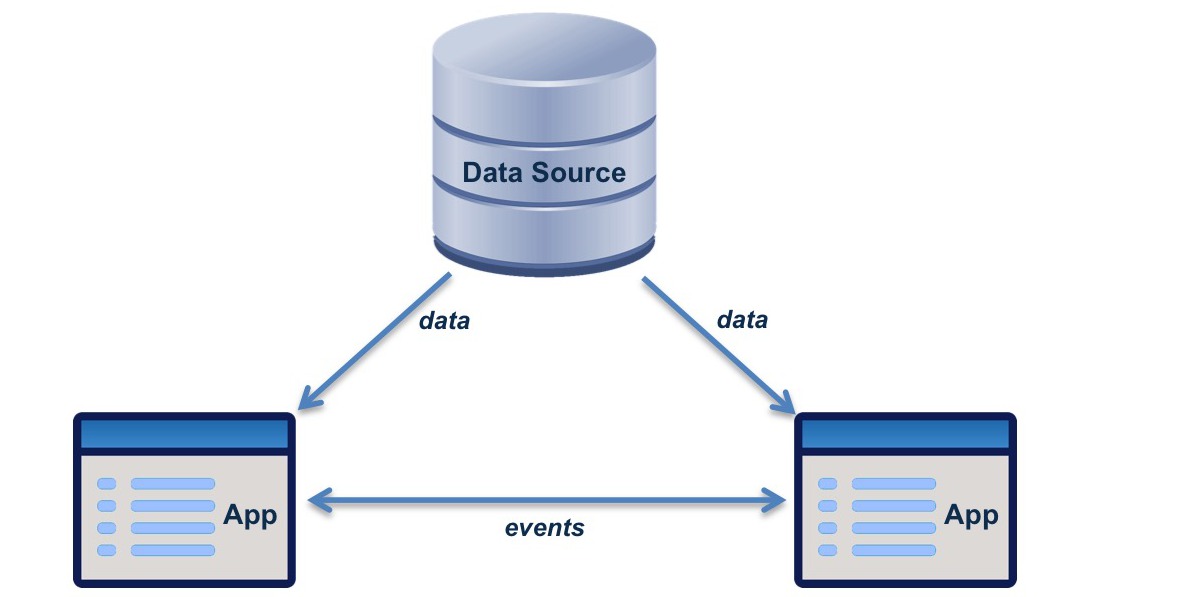 Name: Interoperation by Data Sharing.
Name: Interoperation by Data Sharing.
Statement: Applications interoperate by sharing data, not by exchanging complex messages.
Rationale: Complex point-to-point message structures create undesirable dependencies between applications.
Implications:
- Application messages are usually just event notifications.
- Shared data has minimal structure.
- The benefits of service-orientation are strengthened because services are more independent.
Authoritative Sources
A root cause problem addressed by master data management (Wikipedia, retrieved 14 August 2019) stems from business unit and product line segmentation, in which the same customer will be serviced by different product lines, with redundant data being entered about the customer and account in order to process the transaction. Redundant data can be created in many other ways too. In a data-centered architecture, the customer data (or other redundant data) is contained in a single authoritative source, which is used by the applications for the different product lines, or other user applications. These applications may also use additional sources containing extensions to the common data that are specific to their purposes.
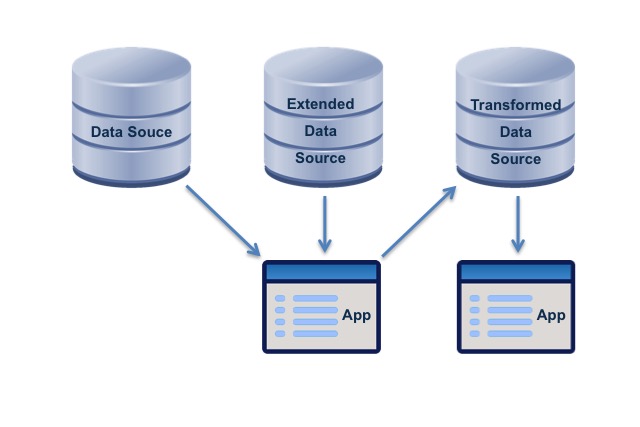 Name: Authoritative Sources.
Name: Authoritative Sources.
Statement: There is a single authoritative source for each piece of data.
Rationale: Having multiple, potentially different, copies of data, with no authoritative source, leads to incorrect execution of business processes and poor quality decisions.
Implications:
- If a piece of data is transformed then the transformed data becomes a new piece of data, with its own authoritative source, which may be different from the source of the original piece of data.
- An application will often combine data from multiple sources. Data virtualization and source-agnostic data models are good approaches to dealing with this situation.
Data Control
Effective management of data, and the ability to use it as a business resource, requires a framework for ownership and control. Establishment of a legal framework for data ownership is proving difficult, but a framework is emerging for control, driven by the need to control use of personal data. This framework can and should be extended to cover data other than personal data.
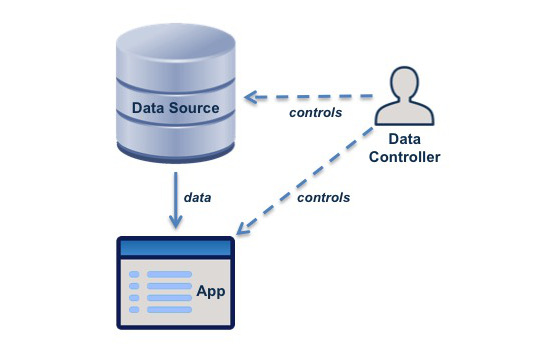 Statement: Each piece of data should have a controller, and the controller should have effective means to control access to it.
Statement: Each piece of data should have a controller, and the controller should have effective means to control access to it.
Rationale: Control of data is the basis of a legal framework for data governance, and can be the basis of a commercial framework that supports data creation and maintenance.
Implications:
- The controller of a piece of data must have control, either physically or through legal provisions and agreements, of its source, of copies, and of processes that transform it.
- The controller of a piece of data has duties and responsibilities to other parties concerned with the data, particularly to people that the data is about.
- An enterprise that is the overall controller will usually delegate that control to a particular department or person.
Metadata Separation
Metadata is data that provides information about other data. Applications can use metadata to process data. By doing this, they become more powerful and more widely usable.
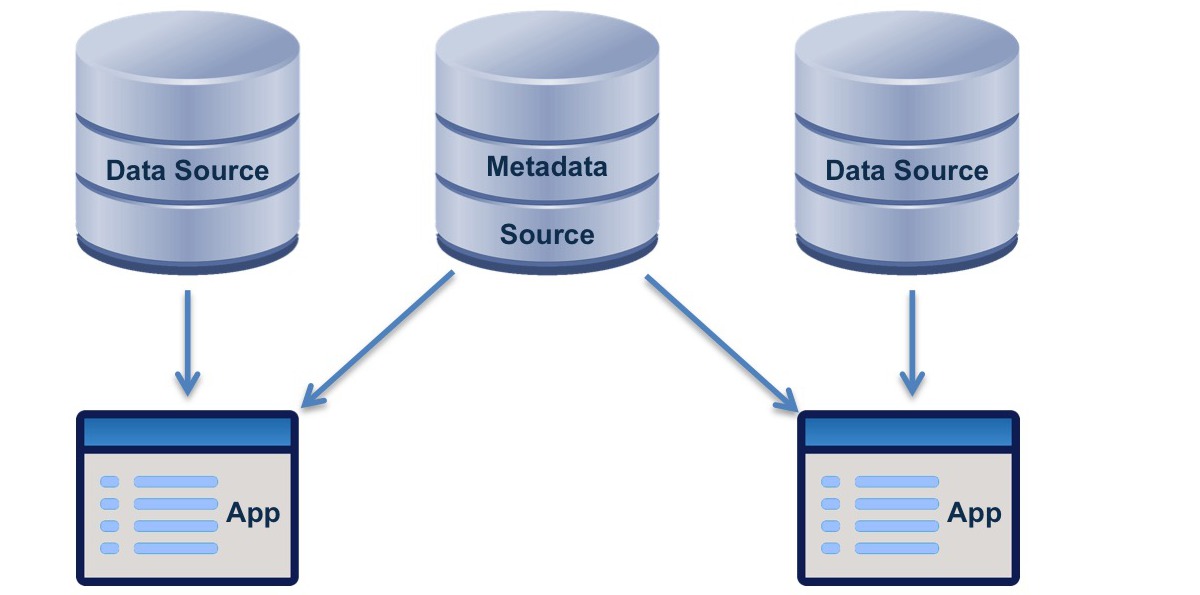 Statement: Metadata and the data that it is about have separate authoritative sources.
Statement: Metadata and the data that it is about have separate authoritative sources.
Rationale: Data from different sources can have common metadata, and applications can consistently interpret the data from any of these sources using the common metadata from a single metadata source.
Implications:
- Definition of metadata is an important aspect of the overall data architecture.
Commercial Model
Creating and maintaining useful high-quality data requires significant effort. It is often hard to recover the cost involved. Once the data is passed to another organization, the provider organization has no control over what copies are taken or who they are given to. Organizations share data with trusted partners who they can rely on to keep agreements, but cannot provide data to a mass market as a profitable service. The music industry, where copying of recordings by customers became commonplace, is a particular example, but the problem applies to data in general.
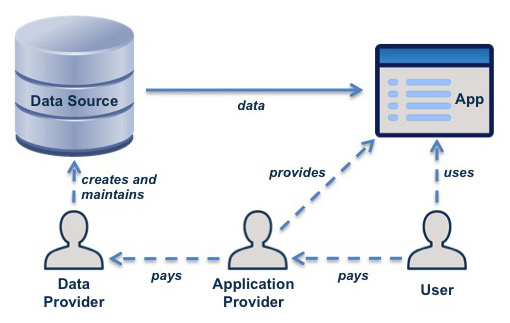 Much data that would be useful is unavailable because providing it is not a viable business.
Much data that would be useful is unavailable because providing it is not a viable business.
The model shown in the figure addresses this problem. It is often used in mobile computing, where data is made available through in-app purchases. A hiking app, for example, may provide a map to users as an in-app purchase. The app company then pays the map company, giving it a source of funding so that it can provide and maintain quality maps. In the music industry, music streaming services with trusted player apps follow this model.
This model is easy to implement in a data-centered architecture, where data is accessed at source, and its owner retains control. The owner shares the data with an application provider, a trusted partner. The application may run on the user's system (as in the case of a mobile app), or be provided as a web service. The application provider makes the data available to end users, but does not make it easy for them to copy it. The user pays the application provider, who pays the data provider.
Data-Centric Manifesto
The Data-Centric Manifesto starts from the premise that the Information Architecture of large organizations is a mess. Until we recognize and take action on the core problem, the situation will continue to deteriorate. The root cause is the prevailing application-centric mindset that gives applications priority over data. The remedy is to flip this on its head. Data is the center of the universe; applications are ephemeral.