Data Virtualization
Virtual data lakes provide a form of data virtualization, but they differ from traditional data virtualization servers in some important respects. They are more flexible, and particularly suited to agile methods and microservice architectures.
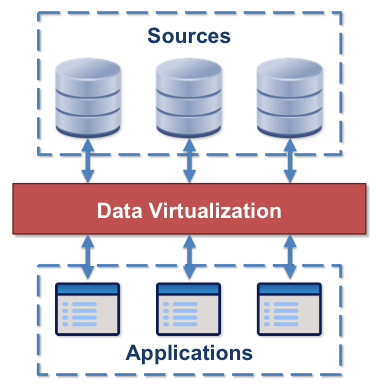 Data virtualization is any approach to data management that allows an application to retrieve and manipulate data without requiring technical details about the data, such as how it is formatted at source, or where it is physically located, and can provide a single customer view (or single view of any other entity) of the overall data. (Wikipedia, retrieved 3rd August 2019)
Data virtualization is any approach to data management that allows an application to retrieve and manipulate data without requiring technical details about the data, such as how it is formatted at source, or where it is physically located, and can provide a single customer view (or single view of any other entity) of the overall data. (Wikipedia, retrieved 3rd August 2019)
Applications can include server- and workstation-based applications of all kinds, mobile apps, and portals giving human users access to the data. In enterprises, data virtualization is often used for business intelligence, analysis and reporting. It can complement or be an alternative to data warehouse and extract-transform-load (ETL) solutions.
Sources of data can include enterprise databases, cloud data stores, Web services, and Web pages. The data can be structured (e.g. relational tables or collections of name-value pairs), semi-structured (e.g. e-mail archives), or unstructured (e.g. PDF documents). It can be "big data" in stores using software such as Hadoop.
The data is often created by applications that access the sources directly rather than through the data virtualization layer: most enterprise applications put data in the enterprise databases directly, mail servers create e-mail archives, and word processing applications create documents. In some cases, applications may use data virtualization to store data. This is not always possible, and is not generally required for the business intelligence, analysis, and reporting applications that are traditionally the main users of data virtualization. Because they do not often write data, data virtualization applications are often referred to as consumers.
Today, the data virtualization layer in most enterprises consists of a data virtualization server. This enables the single overall view of the data that is a key characteristic of data virtualization but, like most monolithic solutions, is inflexible and hard to adapt in an agile way. Having a single server is not the only way to achieve data virtualization; more flexible and agile solutions are possible.
Data Virtualization Servers
Traditional data virtualization servers are designed mainly to take data from sources containing SQL tables and make it available to applications. Their internal architecture is described very well in Data Virtualization for Business Intelligence Systems by Rick van der Lans, and is illustrated in the figure.
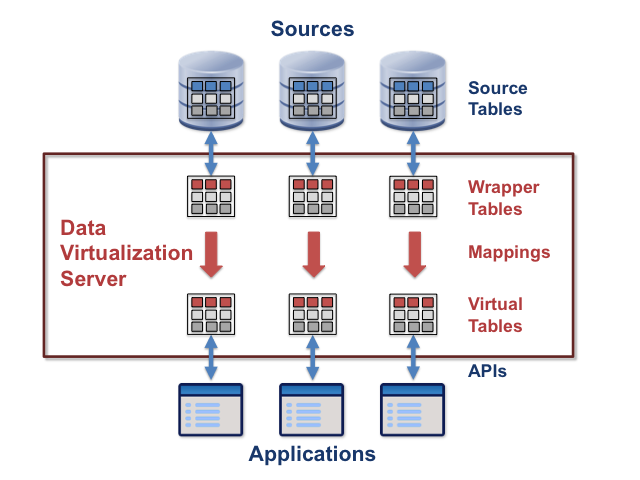 Source tables exist outside the data virtualization server. Where the sources are SQL databases, they are database tables. In other kinds of source, the "source tables" may not have a table structure.
Source tables exist outside the data virtualization server. Where the sources are SQL databases, they are database tables. In other kinds of source, the "source tables" may not have a table structure.
A wrapper table is the server's representation of a source table. If the source table is a database table, the wrapper may specify transformations of column data formats, but otherwise typically preserves the source table structure. In other cases, there can be structural transformations also, for example to flatten heirarchical or repeating elements of XML files to make a relational database table.
A virtual table is a table structured for access by applications, but which contains no data, the data supplied to applications being obtained from the sources. It can be thought of as a view of the data in the sources.
A mapping is a definition of how the data from a source table, or set of source tables, should be transformed to become the contents of a virtual table. A mapping usually consists of operations such as row selections, column selections, column concatenations and transformations, column and table name changes, and groupings. A data virtualization server usually has a language that designers can use to specify mappings.
The APIs are the application interfaces to the data. They usually include APIs based on SQL, such as ODBC and JDBC. They may also include APIs supporting the on-line analytical processing (OLAP) query language MDX, and service interfaces that provide access to the data via an Enterprise Service Bus (ESB) in a Service Oriented Architecture.
In most cases, the sources are relational databases, and the wrappers and virtual tables are also relational. The process of defining the wrappers, virtual tables, and mappings can then be data-driven, supported by tools provided by the server. The definitions of the wrappers and mappings are stored as metadata on the server. A skilled designer can create the definitions relatively easily. For sources that are XML files, or web services that supply XML or JSON files, the process can still use standard transformation languages, such as XSLT and XQuery. For other kinds of source, the process can be more difficult, and may require bespoke programming.
Virtual Data Lakes
A virtual data lake is a data virtualization server whose essential component is a triple store. It need not be a large, enterprise-wide resource; a large number of small virtual data lakes may together serve an enterprise.
A triple, consisting of a subject, verb, and object, is an atomic data unit. Data sets of all kinds, including relational databases, collections of name-value pairs, e-mail archives, and document repositories, can be represented as triples. Traditional data virtualization servers are largely based on relational tables, but can accommodate other data structures, and use mappings to translate between them. Virtual data lakes represent all data as triples. This is a simpler principle, resulting in more flexible solutions.
The figure shows how a virtual data lake is used for data virtualization.
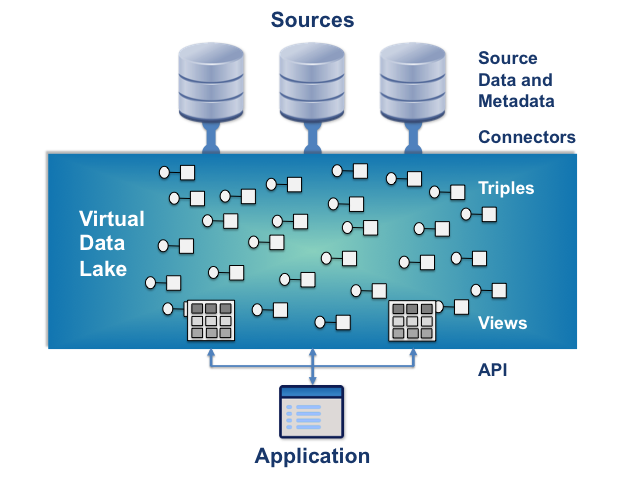 A source can in principle be any kind of data store. (At present, connectors exist only for sources that contain triples.) The sources do not just hold the data used by applications. They also hold the metadata used to define views of that data.
A source can in principle be any kind of data store. (At present, connectors exist only for sources that contain triples.) The sources do not just hold the data used by applications. They also hold the metadata used to define views of that data.
A connector imports data from a source into the triple store, and can also export data from the store to the source. It converts between the source's representation of the data and subject-verb-object triples.
The triples have subjects and verbs that are items, and objects that can be items or data elements. An item can represent an object in the real world, a property of real-world objects, or an abstract concept. A data element can have a simple value (e.g. an integer) or be a piece of text or a blob of data. For example, the subject of a triple could be an item representing the person John Smith, the verb could be an item representing the property has name, and the object could be the text string "John Smith". Another triple could have the same subject, its verb could be an item representing has age, and its object could be the integer 21.
A view is the result set of a stored query on the data. In a virtual data lake, the query takes the form of a request for values defined by a set of constraints on the triples. For example a view of data about people, including John Smith, could be defined by: NAME, AGE where PERSON has name NAME and PERSON has age AGE. This concept is based on (but not quite the same as) the query language SPARQL. The result of such a query looks like the result of an SQL query in a relational database, but can be obtained from data that does not fit the relational model, for example by containing hierarchical or repeating elements.
The queries that define views are stored as metadata in the data sources, not in the virtual data lakes themselves. This means that a query can be used in many virtual data lakes.
The API is a programmatic interface that can be used to define and execute queries, and also to create and delete triples directly. An application could use it to provide a SQL-based API, an MDX API, a web service API, or an ESB interface.
A single virtual data lake can be used by multiple applications, but a more flexible arrangement is for each application, or distributed application component, to have its own virtual data lake. Such applications can have common views of shared data, because the data and the view definitions are held in sources that all their virtual data lakes can connect to. When this approach is followed, the application or application component can be deployed together with its virtual data lake as a single service or microservice.
For example, in an Internet of Things application, microservices deployed in several locations to read sensor data could use their virtual data lakes to store the collected readings in data sources, and a central analysis microservice could produce reports using a single view of the data in the sources.
Summary
Traditional Data Virtualization Servers
- Are a mature concept, with products available from competing suppliers
- Are oriented towards relational data tables and SQL, but can work with a wide range of other data structures and query languages
- Are mainly used as monolithic platforms in enterprises
- Are well suited to enterprise-wide business intelligence, analysis, and reporting applications.
Virtual Data Lakes
- Are a new concept
- Are based on triples, which can represent data of any kind
- Are suited to distributed operation, including in microservices architectures
- Can be used for most applications, and can be a basis for application integration and interoperability.