Virtual Data Lakes
Virtual data lakes enable applications to mix and match data from different sources, applying distributed access control to ensure the right people have the right data.
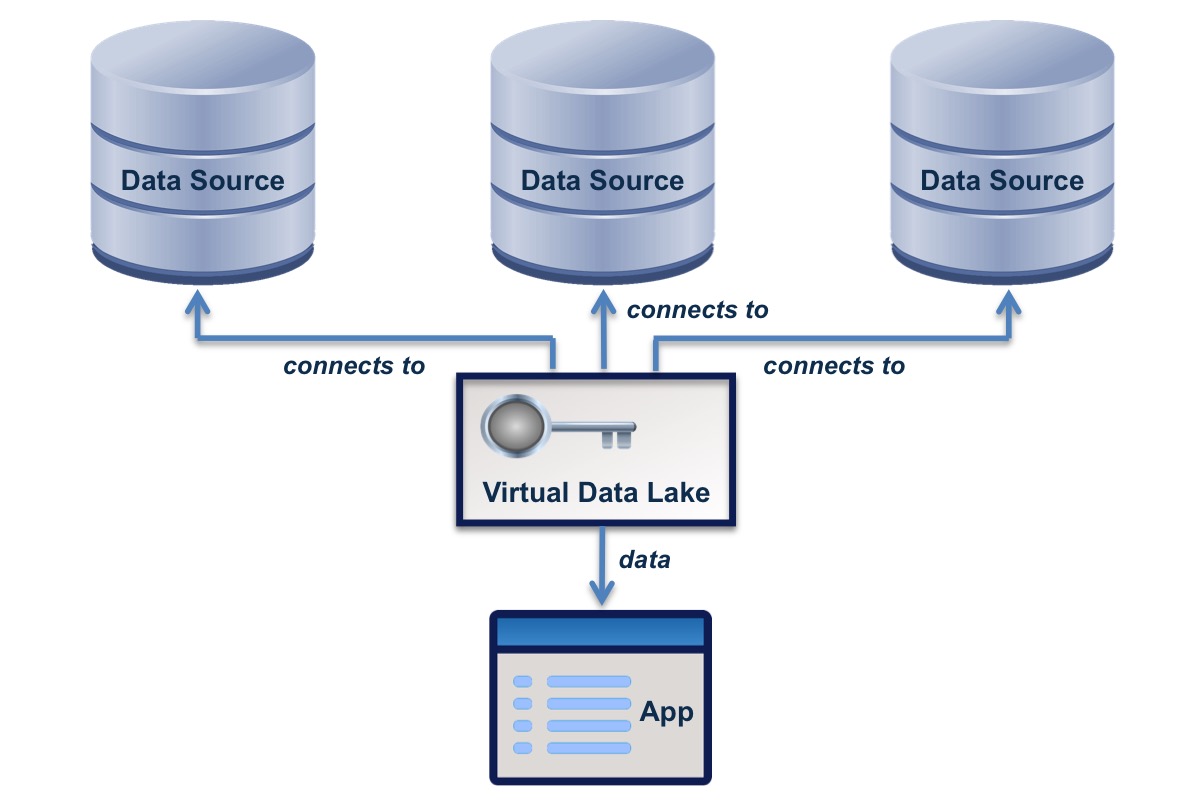 A virtual data lake is connected to or disconnected from data sources as needed by the applications using it. It holds summaries of the data in the sources so that the applications can search the data as though it was a single data set, and can retrieve complete items as needed. It can enable an application to change the data in a source.
A virtual data lake is connected to or disconnected from data sources as needed by the applications using it. It holds summaries of the data in the sources so that the applications can search the data as though it was a single data set, and can retrieve complete items as needed. It can enable an application to change the data in a source.
A virtual data lake applies fine-grained access control so that application users can only see or change data that they are entitled to see or change. The owner of a data source can control access to the data from that source, independently of the owners of other data.
By providing effective control of the data in the sources, virtual data lakes enable the growth of commercial ecosystems that follow the data-centered architecture commercial model.
Virtual data lakes provide a form of data virtualization. They are key building blocks for data-centered architecture.
Virtual data lakes are in some ways similar to traditional enterprise data lakes. Either kind of data lake can provide a good platform for data analysis and integration, but there are significant differences.
Enterprise Data Lakes
An enterprise data lake is a physical data lake. It is a system or repository of data stored in its natural/raw format, usually object blobs or files. It is usually a single store of all enterprise data including raw copies of source system data and transformed data used for tasks such as reporting, visualization, advanced analytics and machine learning. (Wikipedia definition of data lake, retrieved 21 September 2020). An enterprise data lake is often used as an alternative to an enterprise data warehouse, or as a data warehouse front end.
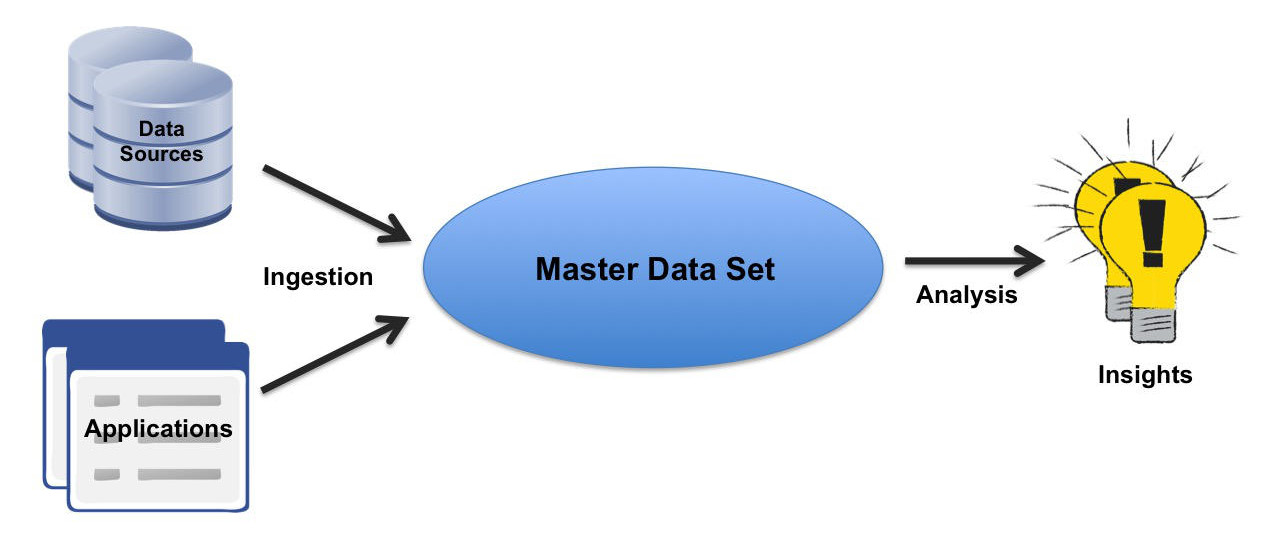 The general concept of operation of an enterprise data lake is described in the Open Business Data Lake (O-BDL) Conceptual Framework standard, and summarized in the figure.
The general concept of operation of an enterprise data lake is described in the Open Business Data Lake (O-BDL) Conceptual Framework standard, and summarized in the figure.
Data is ingested into the master data set from data sources and applications. The data in the master data set is analyzed to produce insights. The insights can gude management decisions and initiate actions. Ingestion may be carried out in real time or in batch mode. Insights can be generated in real time as data is ingested, or by iterative distillation steps that progressively analyze and enrich the data. In parallel with the analysis, unified data management operations are executed to provide metadata management, data quality and governance, data virtualization, and API management.
Virtual Data Lakes in the Enterprise
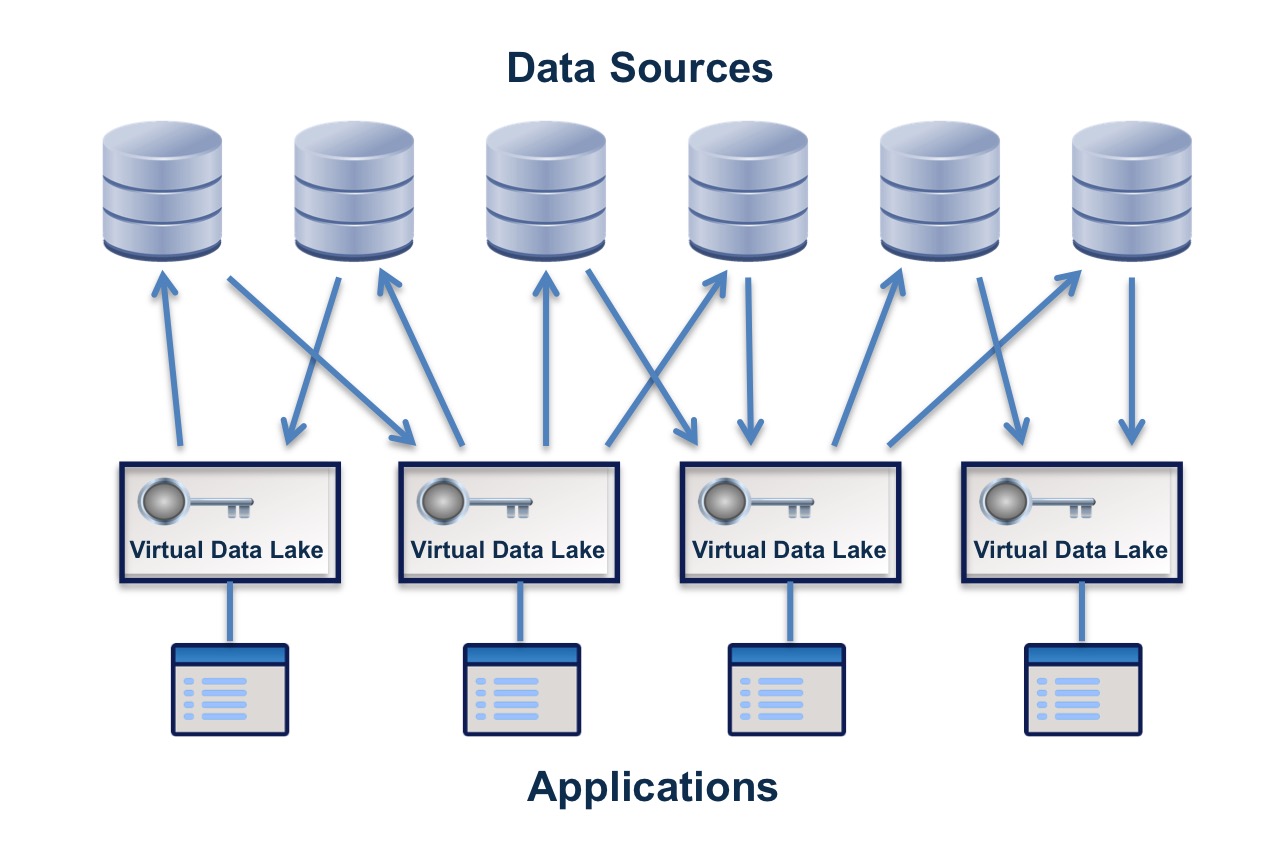 In contrast to an enterprise data lake, a virtual data lake:
In contrast to an enterprise data lake, a virtual data lake:
- Does not store the data, but indexes and caches the data in connected sources
- Does not include all the enterprises data, but connects to the data sources needed for a particular purpose
- Has built-in fine grained access control.
A virtual data lake is not a replacement for an enterprise data warehouse. A virtual data lake typically serves an application, or a set of related applications. These can be analysis applications, that distill data from input sources and create insights in an output source. They can also be business applications that transform and integrate data.
Adoption of virtual data lakes is not a "rip and replace" operation. Virtual data lakes can be introduced gradually, and used in combination with other data processing approaches. They enable new applications to re-use existing data sources without disturbing the operation of existing applications. They are the ultimately flexible way to extend enterprise information capabilities.